“Just as search engines have transformed how we access information, other forms of big-data computing can and will transform the activities of companies, scientific researchers, medical practitioners, and our nation’s defense and intelligence operations.” (Randal E. Bryant, Katz, Lazowska, 2008)
Is business information big data?
No in itself it is not, but it is possible to treat it in the same way and here is an outline of how we may do that and why we may want to.
The process of turning data into information uses and then provides a set of tools for managing many types of critical business process. It stems from reference data and analytical data. Reference data is the process and transactions that comprise the business activity analytical data is abstracted from this to provide support for decisions. The model of OLTP and DSS is well known to data scientists and has informed much of our thinking to date. Nowadays it is becoming more important to blur the edges of the twin pillars of OLTP and DSS at least as far as we examine the data and form it into information.
The schema we held so close to us and that occupied an important place in our affections is coming under pressure from our experience of applications that handle large, unstructured and diverse sets of data, such as Twitter, Google, Facebook. The activity of searching and broadcasting provide more than just a glimpse of the possibility of gathering business knowledge and insights in the same way as we gather information and facts from the web. The challenges, of navigating and finding what you want in big data sets, are solved by a set of data tools that can equally be applied to collections of business data.
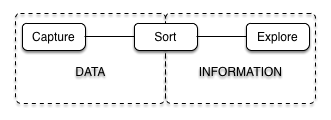
So how do we go about this?
- The first step is capturing the data.
- The second step is to process it and transform it into analysable data.
- The final step is to actually analyse it.
Each step requires a different form of storage.
Capture
At this point the source could be a mixture of filesystem, direct input sources, or textual capture (e.g. from email, documents or online sources or data feeds). This first step involves adding appropriate metadata derived from the capture method and the capture process; source, location, user or user assigned values. The storage at this point could well be column or key pair based.
Sort
The second step is to just extract the data that is meaningful and drop the rest. Aggregate data stores could serve us well here as the process is to search through it and find data that is or ought to be related.
Explore
The third step is to define the relationships and perform transaction searches on the data set and present the data as understandable information. A graph data store may be very appropriate to this stage.
In future posts we will look at what functionality these processes require.
